Introduction to Tensors
Creating tensors
PyTorch tenssors are created using torch.Tensor()= https://pytorch.org/docs/stable/tensors.html
1
2
3
|
import torch
scalar = torch.tensor(7)
scalar
|
1
2
|
# Get tensor back as Python int
scalar.item()
|
1
2
3
|
# Vector
vector = torch.tensor([7, 7])
vector
|
1
|
vector.ndim #number of dimensions
|
1
2
3
4
|
MATRIX = torch.tensor([
[7, 8], [9, 10]
])
MATRIX
|
1
2
3
4
|
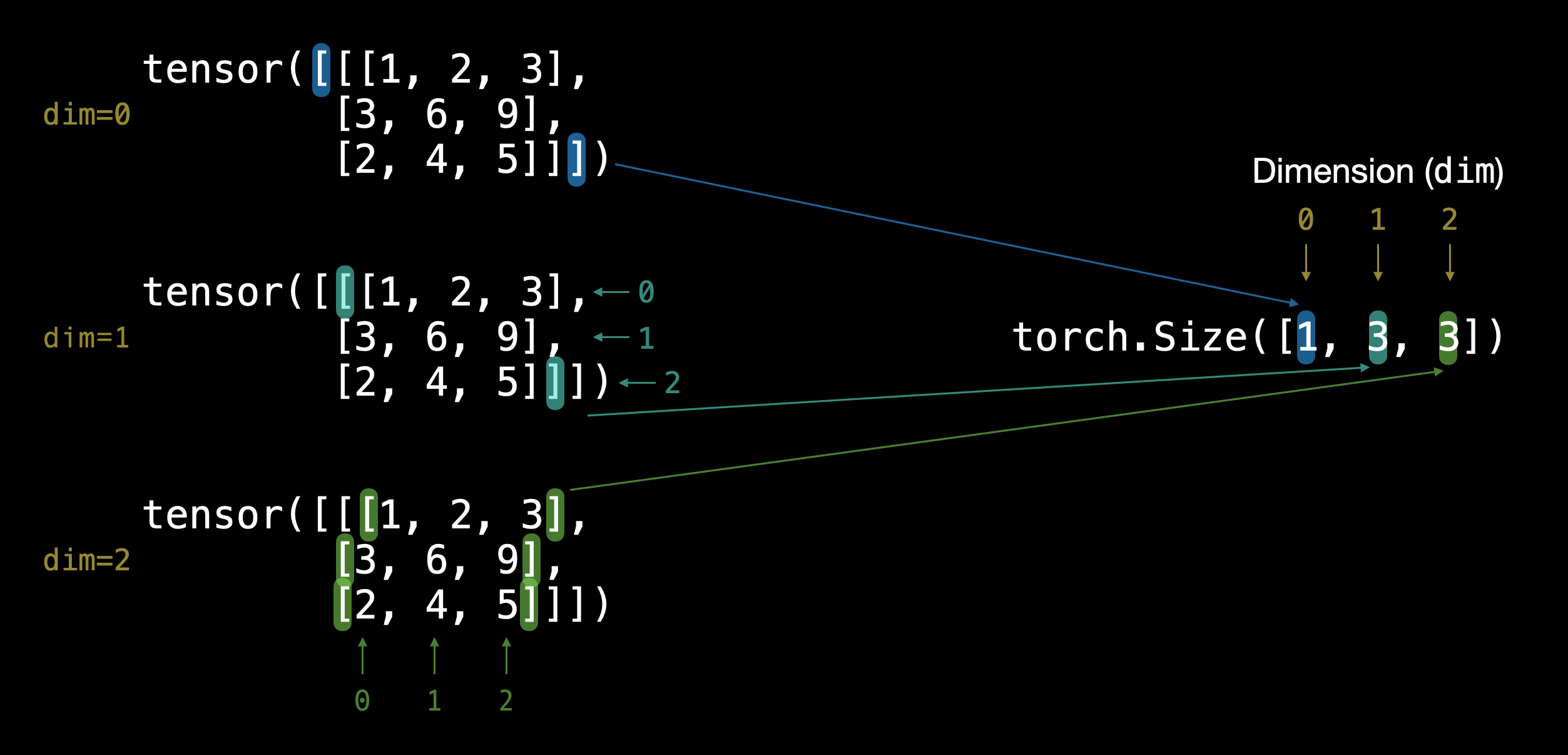
TENSOR = torch.tensor([[
[1, 2, 3], [3, 6, 9], [2, 4, 5]
]])
TENSOR
|
1
2
3
|
TENSOR.shape #The first dimension has a length of 1, indicating that the tensor contains only one element.
#The second dimension has a length of 3, indicating that the tensor contains 3 sublists.
#The third dimension has a length of 2, indicating that each sublist contains 2 elements.
|
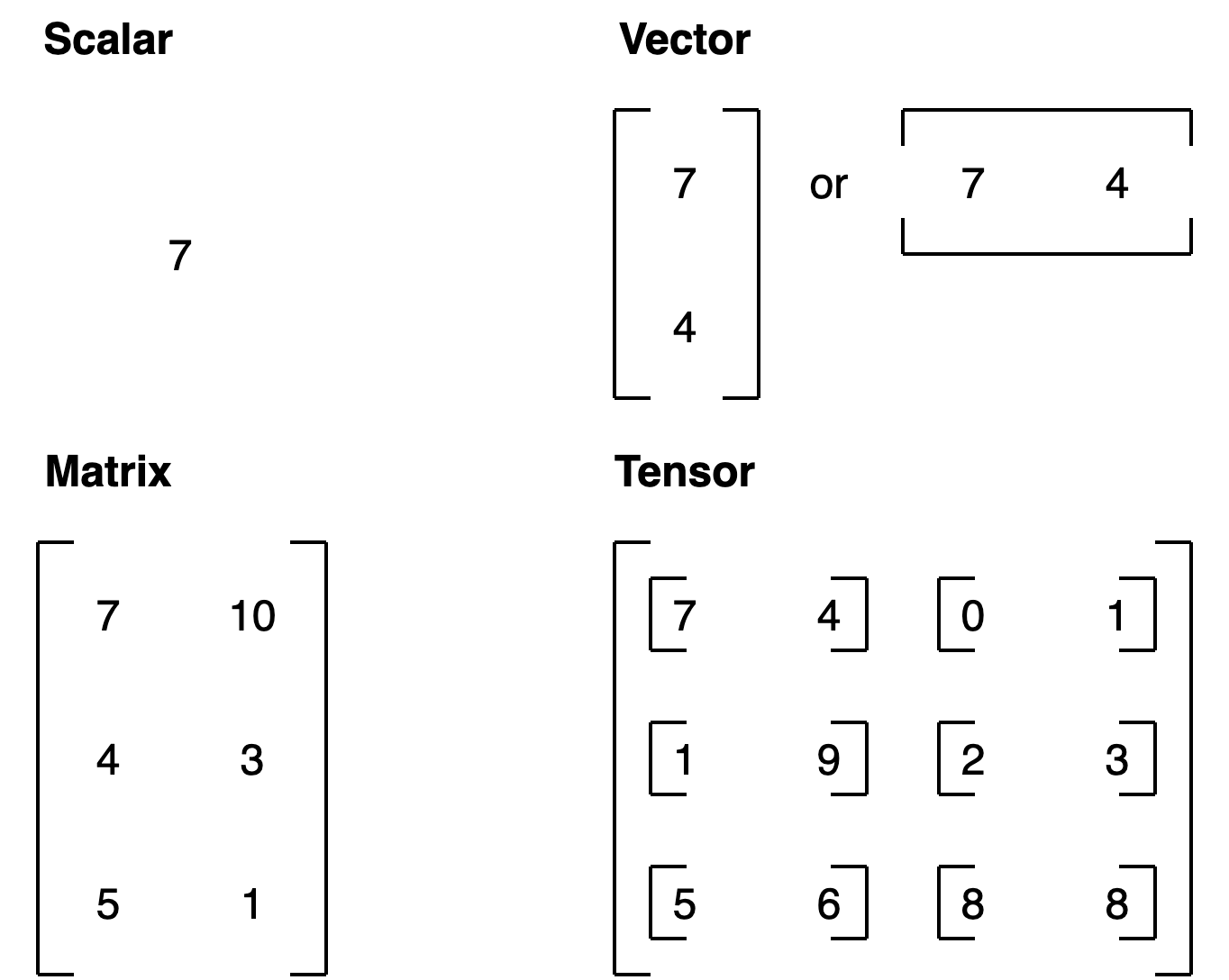
Conclusion
| Name |
What is it? |
Number of dimensions |
Lower or upper (usually/example) |
| scalar |
a single number |
0 |
Lower (a) |
| vector |
a number with direction (e.g. wind speed with direction) but can also have many other numbers |
1 |
Lower (y) |
| matrix |
a 2-dimensional array of numbers |
2 |
Upper (Q) |
| tensor |
an n-dimensional array of numbers can be any number, a 0-dimension tensor is a scalar, a 1-dimension tensor is a vector |
can be any number, a 0-dimension tensor is a scalar, a 1-dimension tensor is a vector |
Upper (X) |
Random tensors
Why random tensors?
Random tensors are important because the way many neural networks learn is that they start with tensors full of random numbers and then adjust those random numbers to better represent the data.
Start with random numbers -> look at data -> update random numbers -> 1look at data -> update random numbers
1
2
3
|
# Create a random tensor of (3, 4)
random_tensor = torch.rand(3, 4)
random_tensor
|
1
2
3
|
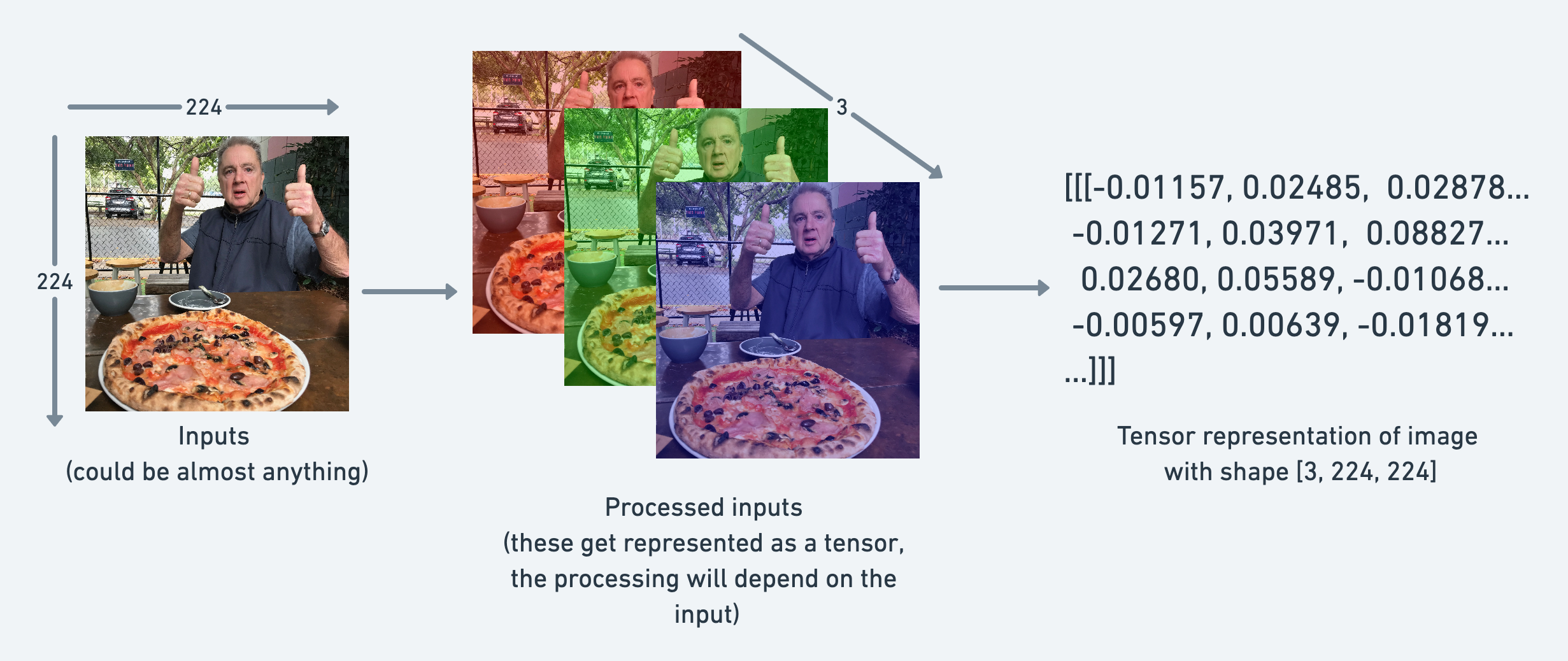
#Create a random tensor with similar shape to an image tensor
random_image_size_tensor = torch.rand(size=(3, 224, 224))
random_image_size_tensor.shape, random_image_size_tensor.ndim
|
You could represent an image as a tensor with shape [3, 224, 224] which would mean [colour_channels, height, width], as in the image has 3 colour channels (red, green, blue), a height of 224 pixels and a width of 224 pixels.
Zeros and ones
1
2
|
zeros = torch.zeros(size=(3, 4))
zero
|
1
2
|
ones = torch.ones(size=(3, 4))
ones
|
Creating a range of tensors and tensors-like
1
2
|
one_to_hundred = torch.arange(start=1, end=100, step=10)
one_to_hundred
|
1
2
|
ten_zeros = torch.zeros_like(one_to_hundred) #same shape
ten_zeros
|
Tensor datatypes
Note: Tensor datatypes is one of the 3 big errors you’ll run into with PyTorch & deep learning:
- Tensor not right datatype
- Tensor not right shape
- Tensor not on the right device
Precision in computing: https://en.wikipedia.org/wiki/Precision_(computer_science)#:~:text=ln%20computer%20science%2C%20the%20precision,used%20to%20express%20a%20value
1
2
3
4
5
|
float_32_tensor = torch.tensor([3.0, 6.0, 9.0],
dtype=None,
device=None,
requires_grad=False)
float_32_tensor
|
In PyTorch, dtype, device, and requires_grad are key parameters of the torch.tensor() function used to define the tensor’s data type, device, and gradient computation settings.
dtype: Represents the data type of the tensor. Common data types include floating-point numbers, integers, etc. Different data types can be used when creating tensors. Common data types include torch.float32 (default), torch.float64, torch.int32, etc.
Optional parameters:
torch.float32 (or torch.float): 32-bit floating-point numberstorch.float64 (or torch.double): 64-bit floating-point numberstorch.int8, torch.int16, torch.int32, torch.int64: Represent 8-bit, 16-bit, 32-bit, and 64-bit signed integers, respectivelytorch.uint8: 8-bit unsigned integers
device: Indicates the device on which the tensor resides, such as CPU or GPU. PyTorch supports creating tensors on different devices, and tensors can be placed on specific devices by setting the device parameter.
Optional parameters:
torch.device('cpu'): Place the tensor on the CPUtorch.device('cuda'): Place the tensor on the default CUDA device (GPU)torch.device('cuda:0'): Place the tensor on the specified CUDA device, e.g., the first GPUtorch.device('cuda:1'): Place the tensor on the specified CUDA device, e.g., the second GPU
requires_grad: Indicates whether the gradients of the tensor need to be computed. If set to True, it means that all operations performed on the tensor will be tracked for subsequent gradient computation. This is crucial for parameter optimization and backpropagation in neural networks.
Optional parameters:
True: Indicates that gradients need to be computedFalse: Indicates that gradients do not need to be computed
1
2
|
float_16_tensor = float_32_tensor.type(torch.float16)
float_16_tensor
|
1
|
p = float_16_tensor * float_32_tensor
|
- Tensors not right datatype - to do get datatype from a tensor, can use
tensor.dtype
- Tensors not right shape - to get shape from a tensor, can use
tensor.shape
- Tensors not on the right device - to get device from a tensor, can use
tensor.device
1
2
|
some_tensor = torch.rand(2, 3)
some_tensor
|
1
2
3
4
|
print(some_tensor)
print(f"Datatypte pof tensor: {some_tensor.dtype}")
print(f"Size pof tensor: {some_tensor.shape}")
print(f"Device pof tensor: {some_tensor.device}")
|
Manipulating Tensors (tensor operations)
Tensor opertions include:
- Addition
- Subtraction
- Multiplication (element-wise)
- Division
- Matrix multiplication
1
2
3
4
|
tensor = torch.tensor([
1, 2, 3
])
print("",tensor+10,"\n",tensor*10,"\n",tensor-10)
|
Matrix multiplication
Two main ways of performing multiplication in neural networks and deep learning:
- Element-wise mutltiplicaiton
- Matrix mutliplicaiton(dot product)
More information - https://www.mathsisfun.com/algebra/matrix-multiplying.html
There are two main rules that performing matrix mutliplication needs to satisfy:
- The inner dimensions must match:
(3, 2) @ (3, 2) won’t work(2, 3) @ (3, 2) will work(3, 2) @ (2, 3) will work
- The resulting matrix has the shape of the outer dimensions:
(2, 3) @ (3, 2) -> (2, 2)(3, 2) @ (2, 3) -> (3, 3)
More information: http://matrixmultiplication.xyz
1
|
torch.matmul(tensor, tensor)
|
1
2
3
4
5
6
|
%%time
value = 0
for i in range(len(tensor)):
value+= tensor[i] * tensor[i]
value
|
1
2
|
%%time
torch.matmul(tensor, tensor)
|
One of the most common errors in deep learning: shape errors
1
2
3
4
5
6
|
tensor_A = torch.tensor([
[1, 2],
[3, 4],
[5, 6],
])
tensor_A
|
1
2
3
4
5
6
|
tensor_B = torch.tensor([
[7, 8],
[9, 10],
[11, 12],
])
tensor_B
|
1
2
|
# torch.mm(tensor_A, tensor_B) # torch.mm is the same as torch.matmul
torch.matmul(tensor_A, tensor_B) # it will not work
|
To fix our tensor shape issues, we can manipulate the shape of one of our tensors using a transpose.
A transpose switches the axes or dimensions of a given tensor.
1
|
torch.mm(tensor_A, tensor_B.T)
|
Finding the min, max, mean, sum, etc(tensor aggregation)
1
2
|
x = torch.arange(0, 100, 10)
x
|
1
2
3
|
print(torch.min(x), x.min())
print(torch.max(x), x.max())
print(torch.mean(x.type(torch.float32)), x.type(torch.float32).mean())
|
Finding the postional min and max
Reshaping, stacking, squeezing and unsqueezing tensors
- Reshaping- reshapes an input tensor to a defined shape
- View - Return a view of an input tensor of certain shape but keep the same memory as the original tensor
- Stacking - combine multiple tensors on top of each other(vstack) or side by side (hstack)
- Squeeze - removes all 1 dimensions from a tensor
- Unsqueeze - add a 1 dimension to a target tensor
- Permute - Return a view of the input with dimensions permuted (swapped) in a certain way
1
2
|
b = torch.arange(1., 11.)
b, b.shape
|
1
2
|
c = b.reshape(2, 5) #keep the mumber of elements same
c
|
1
2
|
d[:, 1] = 111 #changing d changges b
d, b
|
1
2
|
b_stacked = torch.stack([b, b], dim=1)
b_stacked
|
1
2
|
x = torch.zeros(2, 1,2,1,2)
x
|
Indexing (selecting data from tensors)
Indexing with PyTorch is similar to indexing with NumPy.
1
2
|
x = torch.arange(1, 10).reshape(1, 3, 3)
x, x.shape
|
PyTorch tensors & NumPy
NumPy is a popular scientific Python numer ical computing 1ibrary .
And because of this, PyTorch has functionality to interact with it.
-
Data in NumPy,want in PyTorch tensor -> torch.from_numpy(ndarray)
-
PyTorch tensor-> NumPy -> torch.Tensor.numpy()
1
2
3
4
5
|
import numpy as np
array = np.arange(1.0, 8.0)
tensor = torch.from_numpy(array).type(torch.float32)
array, tensor
|
1
|
array.dtype, tensor.dtype
|
1
2
3
|
tensor = torch.ones(7)
numpy_tensor = tensor.numpy()
tensor, numpy_tensor
|
Reproducbility (trying to take random out of random)
In short how a neural network learns:
start with random numbers -> tensor operations -> update random numbers to try and make them of the data -> again -> again -> again...
To reduce the randomness in neural networks and PyTorch comes the concept of a random seed.
Essentially what the random seed does is “flavour” the randomness.
1
2
3
4
5
|
random_tensor_A = torch.rand(3, 4)
random_tensor_B = torch.rand(3, 4)
print(random_tensor_A)
print(random_tensor_B)
|
1
|
print(random_tensor_A == random_tensor_B)
|
1
2
3
4
5
6
7
8
9
|
RANDOM_SEED = 42
torch.manual_seed(RANDOM_SEED)
random_tensor_C = torch.rand(3, 4)
torch.manual_seed(RANDOM_SEED)
random_tensor_D = torch.rand(3, 4)
print(random_tensor_C == random_tensor_D)
|
Running tensors and PyTorch objects on the GPUs (and making faster computations)
GPUs = faster computation on numbers, thanks to CUDA + NVIDIA hardware + PyTorch working behind the scenes
dory (good).
1
2
3
4
|
torch.mps.is_available()
#device = "mps" if torch.cuda.is_available() else "cpu"
#device
|
1
2
3
4
5
6
7
|
# if use macbook
if torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
print("Using device:", device)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
import torch
import torch.nn as nn
import torch.nn.functional as F
import time
# 定义一个卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=5)
self.conv2 = nn.Conv2d(32, 64, kernel_size=5)
self.fc1 = nn.Linear(1024, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(x.size(0), -1) # 展平
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
def test_performance(device):
print(f"Testing on {device}")
model = SimpleCNN().to(device)
data = torch.randn(64, 1, 28, 28, device=device) # 假设输入像 MNIST 图像
# 开始计时
start_time = time.time()
# 运行模型
for _ in range(100000):
output = model(data)
# 计算总时间
total_time = time.time() - start_time
print(f"Total time on {device}: {total_time:.4f} seconds\n")
# 检查 MPS 支持
if torch.backends.mps.is_available():
test_performance("mps")
else:
print("MPS not available. Testing only on CPU.")
# 测试 CPU 性能
test_performance("cpu")
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import nbformat
from nbconvert import MarkdownExporter
md_exporter = MarkdownExporter()
md_exporter.exclude_output = True
notebook_filename = 'PyTorch_Fundamental_2.ipynb'
with open(notebook_filename, 'r', encoding='utf-8') as f:
notebook_node = nbformat.read(f, as_version=4)
markdown, resources = md_exporter.from_notebook_node(notebook_node)
with open('PyTorch_Fundamental_2.md', 'w', encoding='utf-8') as f:
f.write(markdown)
|